Pinokio + Qwen3-TTS 완전 정복 가이드! 초보자도 10분 만에 로컬 TTS + 감정 목소리 + 음성 클로닝 마스터하기
Qwen3-TTS에 실제 생성한 음성입니다.
2026년 최고의 오픈소스 TTS 모델 Qwen3-TTS를 Pinokio 하나로 쉽게 돌리는 방법!
감정이 살아있는 목소리부터 3~10초 짧은 음성으로 목소리 복제까지, 기본부터 실전 사용기까지 자세히 알려드려요. 코딩 몰라도 OK!
1. Pinokio란? 왜 이제 AI 초보자 필수 앱인가?
Pinokio는 “로컬 AI 앱 브라우저”예요. 복잡한 터미널 명령어, 파이썬 환경 설정, GPU 드라이버 설치 같은 귀찮은 과정을 완전히 없애줍니다. 한 번 설치하면 클릭 몇 번으로 ComfyUI, Stable Diffusion, FaceFusion, 그리고 지금 말씀드릴 Qwen3-TTS까지 설치·실행·관리할 수 있어요.
주요 장점:
- 완전 무코드(노코드) → 마우스 클릭만으로 설치
- 로컬 실행 → 인터넷 없이 프라이버시 100% 보호
- 자동 업데이트 + 충돌 관리
- Windows / macOS / Linux 모두 지원
Pinokio를 설치하면 “로컬 클라우드”가 내 PC에 생기는 셈이에요. 이제 Qwen3-TTS 같은 고성능 TTS도 5분 만에 돌릴 수 있습니다!
2. Qwen3-TTS란? 2026년 최강 오픈소스 TTS 모델
알리바바 Qwen 팀이 2026년 1월 오픈소스로 공개한 최신 TTS 모델 패밀리예요. 0.6B(경량)와 1.7B(고성능) 두 가지 크기로 나뉩니다.
- 주요 특징: 10개 언어(한국어·영어·중국어·일본어 등) 완벽 지원, 초저지연(97ms), 스트리밍 생성 가능
- Voice Cloning: 3~10초 정도의 짧은 음성만으로 목소리 복제
- Voice Design: 자연어로 “흥분한 목소리로”, “슬프고 눈물 섞인 톤으로” 같은 지시 가능
- 감정·억양 제어: 텍스트 의미를 이해해 자동으로 리듬·톤·감정 조절
상용 ElevenLabs급 품질을 로컬에서 무자본으로 사용할 수 있다는 점이 최대 강점입니다!
3. Pinokio로 Qwen3-TTS 설치·실행하는 방법 (초보자 10분 완성)
- Pinokio 공식 사이트(pinokio.co)에서 다운로드 → 설치 (설치 후 자동 실행)
- Pinokio 창에서 오른쪽 상단 “Discover” 또는 “Community” 탭 클릭
- 검색창에 “Qwen3-TTS” 또는 “Qwen3 TTS MLX WebUI Enhanced” 입력
- 가장 많이 설치된 WebUI 앱(보통 Blizaine 버전)을 선택 → “Install” 클릭 (자동으로 모델 다운로드 시작)
- 설치 완료 후 “Launch” 버튼 → 브라우저에서 WebUI가 열림
- 처음 실행 시 1.7B 또는 0.6B 모델 자동 다운로드 (VRAM 8GB 이상 권장, 1.7B은 12GB 이상이 이상적)
설치 끝! 이제 브라우저 안에서 모든 작업이 가능합니다.
4. 기본 사용법: 텍스트 → 음성 생성하기
WebUI 상단에 “Text-to-Speech” 또는 “Generate” 탭이 있습니다.
- 텍스트 입력창에 원하는 문장 입력
- 스피커 선택 (기본 프리셋 목소리)
- “Generate” 버튼 클릭 → 몇 초 만에 음성 파일(WAV) 다운로드
스트리밍 모드도 지원하니 긴 문장도 실시간으로 들을 수 있어요.
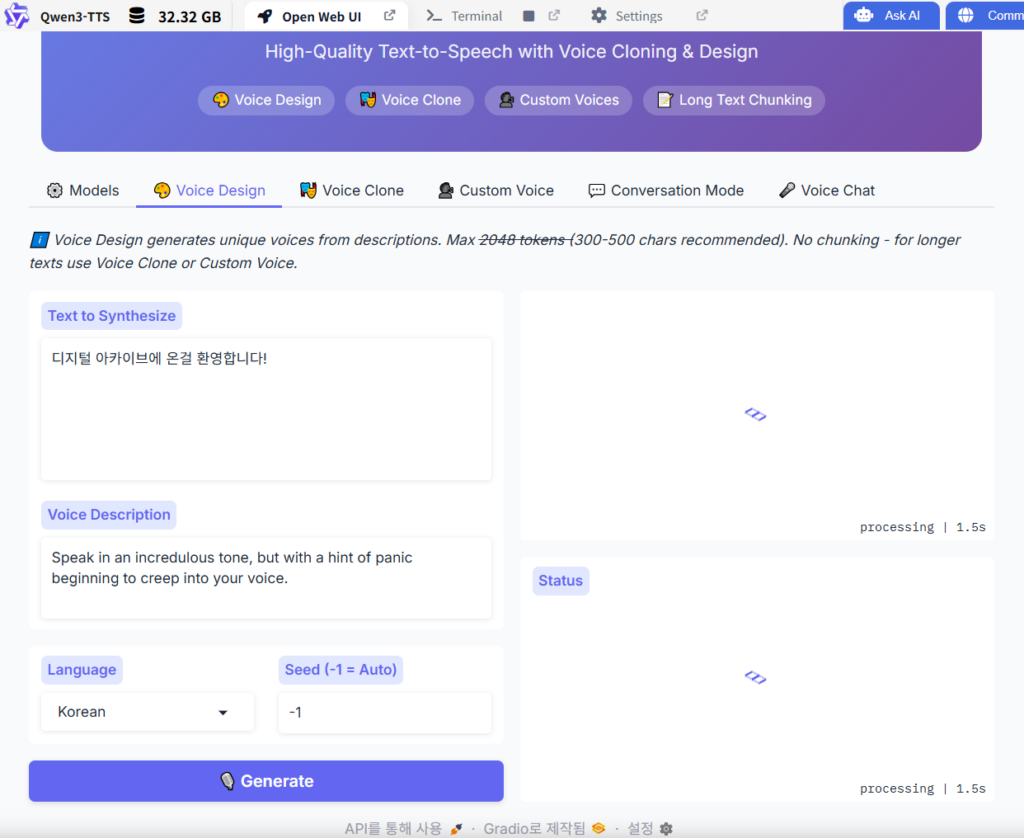
5. Qwen3-TTS로 감정이 섞인 목소리 구현 방법 (Voice Design)
여기서 Qwen3-TTS의 진짜 힘이 나옵니다! “Custom Voice” 또는 “Voice Design” 탭으로 이동하세요.
자연어 프롬프트 예시
- “흥분하고 밝은 목소리로, 빠른 템포로 말해”
- “슬프고 눈물 섞인, 낮고 떨리는 톤으로”
- “화가 나서 거칠게, 하지만 조금은 애원하는 느낌으로”
- “차분하고 부드럽게, 위로하는 듯한 목소리로 천천히”
1.7B 모델을 쓰면 감정 표현이 훨씬 자연스럽습니다. 여러 문장을 이어서 쓰면 대화체 감정 변화도 가능해요. “먼저 기쁘게 말하다가 점점 슬퍼지며…” 같은 지시도 잘 먹힙니다.
6. 짧은 음성으로 목소리 복제 (Voice Cloning) – 감정은 넣지 못하는 이유와 실전 팁
“Voice Clone” 탭에서 진행합니다.
- Reference Audio 업로드 (3~10초 정도의 깨끗한 음성 추천)
- Reference Text 입력 (원본 음성이 실제로 말한 내용)
- 복제할 텍스트 입력 → Generate
중요 주의사항: 클로닝 모드는 목소리의 ‘음색(timbre)’과 ‘억양 패턴’만 복제합니다. 감정·톤·속도 제어는 거의 불가능합니다. 클로닝된 목소리는 기본적으로 중립적·평범한 감정으로 나옵니다.
감정을 넣고 싶다면?
- 먼저 Voice Clone으로 목소리를 복제
- 그 클로닝된 목소리를 Custom Voice / Voice Design 탭에서 “reference voice”로 지정
- 자연어로 감정 프롬프트를 추가 (예: “위에서 클론한 목소리로, 화난 듯이 말해”)
이렇게 하면 클로닝 + 감정 조합이 가능해집니다. (1.7B 모델 추천)
“3초 음성만으로 연예인 목소리를 복제하고, 그 목소리로 ‘울면서 사과하는’ 연기를 시키는 게 가능해졌어요. 진짜 영화 OST나 팟캐스트 제작에 혁명입니다!” – 실제 사용자 후기
7. 실전 고급 팁 & 자주 묻는 질문
• VRAM 부족 시 0.6B 모델 사용
• 긴 문장은 문장 단위로 나누어 생성 후 합치기
• 감정 연속성 원하면 “이전 문장의 감정을 이어서…”라고 프롬프트에 명시
트러블슈팅
• 모델 다운로드 안 될 때 → Pinokio 재시작 + VPN OFF
• 음질이 낮을 때 → 1.7B 모델 + “high quality” 프롬프트 추가
• 클로닝 후 감정 안 먹힐 때 → Custom Voice 탭에서 reference voice 재지정
여러분은 Qwen3-TTS로 어떤 목소리를 만들어 보셨나요?
클로닝 성공 사례나 감정 프롬프트 공유 댓글로 남겨주세요! 🎤✨